ELF files intro
Before starting to dive into malware from either an attackers or defenders perspective, you got to understand at least a little bit about what ELF files are, and why they're useful (in a security context).
What is an ELF file?
The Executable and Linkable Format (ELF) is the standard binary format used in Linux / Unix systems. It is used for, of course, executables, and shared library files (.so).
To understand a binary at a system level, you need to understand ELF, we'll get to how this is important to malware analysis and development after we explain the basic structure of the file.
ELF at a high level
The file is made up of:
- The header, which is followed by file data, which can be:
- Program header table
- Section header table
- Data which is referred to by either the program or section header
The header
The header, which we can print out using the readelf command, contains the following:
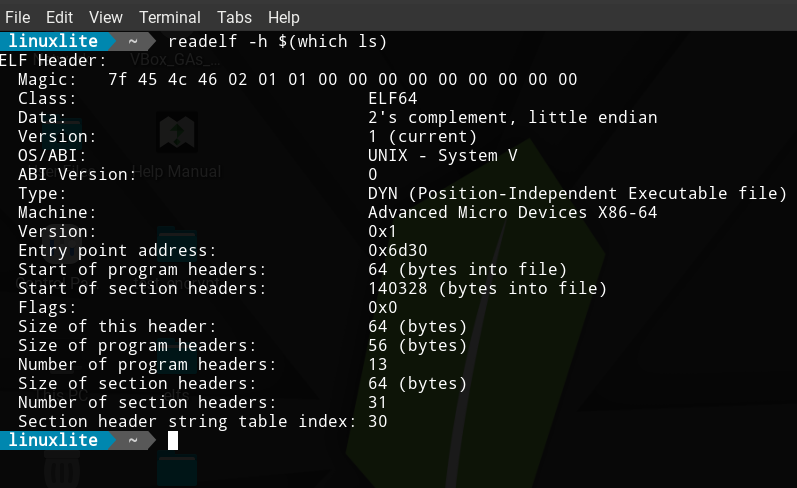
Due to the fact of how extensible the design of ELF files is, the structure is going to be different for different files. The header, for us, is like a road-map with which we can orient ourselves and "move" through the other sections.
We can see that the header starts with a Magic value, showing that this file is an ELF -> the 7f prefix followed by E L and F.
Class is self explanatory, it determines the architecture of the file, it holds either a 32 bit (01) or a 64 bit (02) architecture. In the magic we can see the 02 which is translated by readelf as ELF64.
Data field is defined by the following value in Magic, 01 for little endian and 02 for big endian.
The Type tells us the purpose of the file:
- CORE (value 4)
- DYN Shared object file (value 3)
- EXEC Executable file (value 2)
- REL Relocatable file (value 1)
Now we get to the stuff that's useful for us and that we'll be using in our code.
We see the address of the entry point (the initial instruction executed when loading the executable)
And we see the offsets for the start of the program and section headers.
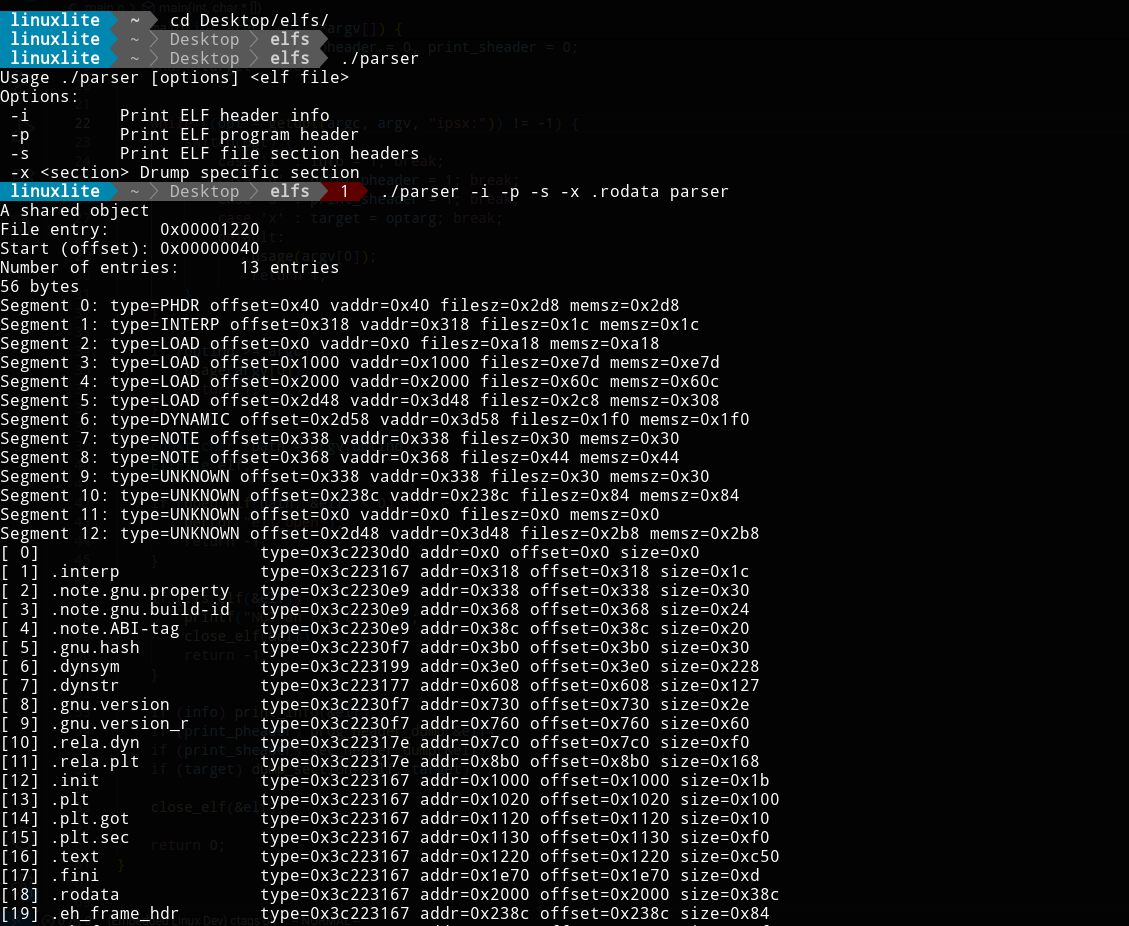
Let's look at the program header table:
Program Header
The program headers tell the loader about how to map the file into memory and prepare it for execution.
Some segments included in the program header are: .text - which contains executable code like functions .rodata - contains read only data such as string literals .data - contains mutable runtime data for initialized variables .dynsym - Dynamic linker symbol table that is used by the dynamic linker
Program headers are made up of :
- Type -> can be, for example, PT_LOAD (loadable) or PT_DYNAMIC (for dynamic linking)
- Offset -> The offset from the start of the file to the byte of the 1st segment
- Virtual Address -> Address to which the segment will be mapped at runtime
- File size
- Mem size -> required memory size of segment when loaded
- Flags -> Permissions like R W and X (read, write, execute)
- Align
You can check this out yourself using readelf -l
Section Header
The section header contains entries of each section in the ELF file from a linkable point of view, each section belongs to a segment (that we showed examples of above).
Some common sections are:
- .text – executable code (functions)
- .rodata – read-only data like strings
- .data – initialized writable data
- .bss – uninitialized data (in memory but not stored in the file)
- .symtab / .dynsym – symbol tables
- .strtab / .dynstr – string tables
- .init_array / .fini_array – functions run before/after main
Section headers are made up of:
- Name → index into string table (for example, text)
- Type → section type (PROGBITS, NOBITS, SYMTAB, etc.)
- Flags → ALLOC, WRITE, EXECINSTR
- Address → runtime virtual address
- Offset → file offset to the section data
- Size → section size
- Link / Info
- Align
- Entry size → size of table entries
You can check this out yourself using readelf -S.
Lets get to the code to parse the sections.
In order to parse the sections -> we need elf.h which you can read about here https://man7.org/linux/man-pages/man5/elf.5.html
First thing we gotta do is open our elf file, as described above, the header contains our "road-map" to the rest of the file.
I map the file into memory as it's easier than loading the entire file into a buffer, and we don't need anything else than read only parsing.
For that I am using a simple struct
typedef struct {
void *map;
size_t size;
Elf64_Ehdr *eh;
} ElfFile;
The added benefit is that we can access other fields by casting the region to Elf64_Ehdr* as you'll see, malicious software does this a lot so it's good to understand.
int open_elf(const char *path, ElfFile *elf) {
int fd = open(path, O_RDONLY | O_SYNC);
if (fd < 0) return -1;
struct stat st;
if (fstat(fd, &st) == -1) {
handle_error("fstat");
}
elf->size = st.st_size;
elf->map = mmap(NULL, elf->size, PROT_READ, MAP_PRIVATE, fd, (off_t)0);
close(fd);
if (elf->map == MAP_FAILED) return -1;
elf->eh = (Elf64_Ehdr *)elf->map;
return 0;
}
int close_elf(ElfFile *elf) {
if (elf->map && elf->map != MAP_FAILED) {
munmap(elf->map, elf->size);
}
}
First we identify that the file we're opening is in fact an ELF file.
We talked about the magic number in the header.
When reading the documentation of <elf.h> we see that the magic num is held in the e_ident array.
Checking is simple:
int is_elf(ElfFile *elf) {
return strncmp((char *)elf->eh->e_ident, "\x7F""ELF", 4) == 0;
}
I will not be implementing full functionality of an ELF file parser, just some particular fields, this is for practice anyway.
Lets actually print some information from the header, we can use e_type to get information on the type of the file, as well as e_phoff, e_phnum, and e_phentsize to get the offset, number of entries, the actual entries and bytes.
void print_info(ElfFile *elf_file) {
Elf64_Ehdr *eh = elf_file->eh;
switch(eh->e_type) {
case ET_NONE:
printf("Unknown type (0x00)\n");
break;
case ET_REL:
printf("A relocatable file\n");
break;
case ET_EXEC:
printf("An Executable File\n");
break;
case ET_DYN:
printf("A shared object\n");
break;
case ET_CORE:
printf("A core file\n");
break;
};
// print entry
printf("File entry:\t");
printf("0x%08lx\n", eh->e_entry);
// print offset
printf("Start (offset):\t");
printf("0x%08lx\n", eh->e_phoff);
printf("Number of entries:\t");
printf("%d entries\n", eh->e_phnum);
printf("%d bytes\n", eh->e_phentsize);
}
Now we get to the fun part, lets dump the program header.
It should be clear by now that in order to get to the program header, we need to add the offset of it (indicated by e_phoff to the program header)
void prog_header_dump(ElfFile *elf_file) {
Elf64_Ehdr *eh = elf_file->eh;
Elf64_Phdr *ph = (Elf64_Phdr *) ((char *)eh + eh->e_phoff);
Now lets dump the segments -> we know that e_phnum shows the number of entries, we can use that to loop through them:
for (int i = 0; i < eh->e_phnum; i++) {
Elf64_Phdr *seg = &ph[i];
printf("Segment %d: type=%s offset=0x%lx vaddr=0x%lx filesz=0x%lx memsz=0x%lx\n",
i,
pt_type(seg->p_type),
seg->p_offset,
seg->p_vaddr,
seg->p_filesz,
seg->p_memsz);
}
}
For the type I wrote a little helper:
const char *pt_type(uint32_t t) {
switch (t) {
case PT_NULL: return "NULL";
case PT_LOAD: return "LOAD";
case PT_DYNAMIC: return "DYNAMIC";
case PT_INTERP: return "INTERP";
case PT_NOTE: return "NOTE";
case PT_PHDR: return "PHDR";
case PT_TLS: return "TLS";
default: return "UNKNOWN";
}
}
To dump the section header we add the e_shoff section header offset, to the Ehdr:
The Section Header Table is literally an array of Elf64_Shdr structs, sitting at file offset e_shoff.
e_shnum tells you how many entries are in the array.
Each Elf64_Shdr describes one section (like .text, .data, .bss, .symtab, etc.)
void sec_header_dump(ElfFile *elf_file) {
Elf64_Ehdr *eh = elf_file->eh;
Elf64_Shdr *sh = (Elf64_Shdr *) ((char *)eh + eh->e_shoff);
sh[i] gives the i-th section header now.
We also need to locate section header string table:
const char *shstrtab = (char *)elf_file->map + sh[elf_file->eh->e_shstrndx].sh_offset;
This is a bit dense so lets break it down:
-
eh->e_shstrndx→ index of the special section that contains the section names.-
Every ELF file has a section called
.shstrtab(section header string table). -
That's where all the section names like
.text,.data,.rodatalive as NUL-terminated strings.
-
-
sh[eh->e_shstrndx]→ gives us the section header entry for.shstrtab -
sh[bla].sh_offset→ file offset to the actual data for that section.- So, this is the start of the string table in the file.
-
elf_file->map + sh_offset→ pointer into the mapped file where the strings are stored.
shstrtab points to the first byte of the .shstrtab section.
From there, we can use sh_name (an integer offset into .shstrtab) to resolve the names.
Now lets walk each section header:
for (int i = 0; i < elf_file->eh->e_shnum; i++) {
const char *name = shstrtab + sh[i].sh_name;
printf("[%2d] %-20s type=0x%x addr=0x%lx offset=0x%lx size=0x%lx\n",
i,
name,
sh_type_str(sh[i].sh_type),
(unsigned long)sh[i].sh_addr,
(unsigned long)sh[i].sh_offset,
(unsigned long)sh[i].sh_size);
}
}
Another helper for the types:
const char *sh_type_str(uint32_t t) {
switch (t) {
case SHT_NULL: return "NULL";
case SHT_PROGBITS: return "PROGBITS";
case SHT_SYMTAB: return "SYMTAB";
case SHT_STRTAB: return "STRTAB";
case SHT_RELA: return "RELA";
case SHT_HASH: return "HASH";
case SHT_DYNAMIC: return "DYNAMIC";
case SHT_NOTE: return "NOTE";
case SHT_NOBITS: return "NOBITS";
case SHT_REL: return "REL";
case SHT_SHLIB: return "SHLIB";
case SHT_DYNSYM: return "DYNSYM";
case SHT_INIT_ARRAY: return "INIT_ARRAY";
case SHT_FINI_ARRAY: return "FINI_ARRAY";
case SHT_PREINIT_ARRAY: return "PREINIT_ARRAY";
case SHT_GROUP: return "GROUP";
case SHT_SYMTAB_SHNDX: return "SYMTAB_SHNDX";
default: return "UNKNOWN";
}
}
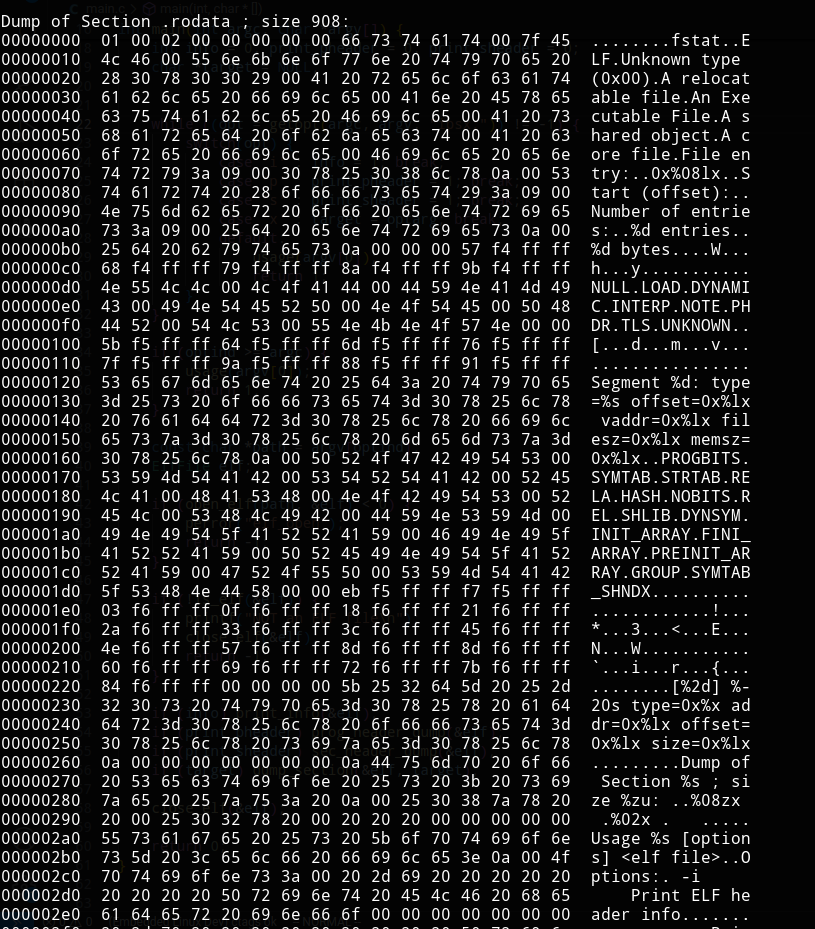
Now to dump each section -> take a section name and print a hex + ASCII dump of the bytes in the section.
We already have the access to it written above:
void dump_section(ElfFile *elf_file, const char* target) {
Elf64_Ehdr *eh = elf_file->eh;
Elf64_Shdr *sh = (Elf64_Shdr *) ((char *)eh + eh->e_shoff);
const char *shstrtab = (char *)elf_file->map + sh[elf_file->eh->e_shstrndx].sh_offset;
....
}
We'll walk through the sections until we find our target section:
for (int i = 0; i < elf_file->eh->e_shnum; i++) {
const char *name = shstrtab + sh[i].sh_name;
if (strcmp(name, target) == 0) {
....
}
}
Each section header has a sh_name which is the offset into shstrtab -> we add it to shstrtab to get the actual string, we compare to the target and if it matches:
unsigned char *sec = (unsigned char *)elf_file->map + sh[i].sh_offset;
size_t size = sh[i].sh_size;
sh_offset is where the section's data is located inside the file, so sec is going to be a pointer to the raw bytes.
And we print it out:
// to know which section is being dumped
printf("\nDump of Section %s ; size %zu: \n", name, size);
// hex dump
for (size_t j = 0; j < size; j += 16) {
printf("%08zx ", j);
for (size_t k = 0; k < 16; k++) {
if (j + k < size)
printf("%02x ", sec[j + k]); // 2 digit padding
else
printf(" "); // fewer than 16 bytes left, align
}
printf(" ");
for (size_t k = 0; k < 16 && j + k < size; k++) {
unsigned char c = sec[j + k];
printf("%c", isprint(c) ? c : '.'); // if printable, print, if not print .
}
printf("\n");
}
Full function :
void dump_section(ElfFile *elf_file, const char* target) {
Elf64_Ehdr *eh = elf_file->eh;
Elf64_Shdr *sh = (Elf64_Shdr *) ((char *)eh + eh->e_shoff);
const char *shstrtab = (char *)elf_file->map + sh[elf_file->eh->e_shstrndx].sh_offset;
for (int i = 0; i < elf_file->eh->e_shnum; i++) {
const char *name = shstrtab + sh[i].sh_name;
if (strcmp(name, target) == 0) {
unsigned char *sec = (unsigned char *)elf_file->map + sh[i].sh_offset;
size_t size = sh[i].sh_size;
printf("\nDump of Section %s ; size %zu: \n", name, size);
for (size_t j = 0; j < size; j += 16) {
printf("%08zx ", j);
//hex
for (size_t k = 0; k < 16; k++) {
if (j + k < size)
printf("%02x ", sec[j + k]);
else
printf(" ");
}
printf(" ");
// ascii
for (size_t k = 0; k < 16 && j + k < size; k++) {
unsigned char c = sec[j + k];
printf("%c", isprint(c) ? c : '.');
}
printf("\n");
}
}
}
}
Test it out: